Appearance
marked extension
2022-10-12
最近、個人的な興味から markdown parser を作っている。1 年ほど前に適当かつ中途半端に作って放置していたものを再度触ってる感じ。
marked の設計にだいぶ引っ張られてはいるが、bundle size には精を出している方で、minify した状態で未圧縮状態で 3kb ほどになっている。(まだ未完成、完成時には 4kb 以下を目指してる)
marked は、markdown を html に変換するライブラリで、node.js でもブラウザでも動く。
marked の設計に引っ張られている以上、plugin の挿し方や、parser の挿し方が近くなりそうな気がしていて、そういうのを挿すことができるようにできるかどうかは置いておいて、一旦知っておく必要があると思った。
今回は、marked の extension について調べて、2 つのカスタムルールを作ってみた。
marked の extension
Extending Marked あたりに書いてある。marked.use(extension) のような形で定義することができるようになっている。
また、複数定義する際には
marked.use(extension1);
marked.use(extension2);
1
2
2
のような形で定義することもできる。
パイプラインについては、普通に形式言語のパーサなりコンパイラを作ったことがある人なら想像の通りで、
- lexer
- tokenizer
- parser
- renderer
に分かれていて、tokenizer と parser の間で walkTokens という関数があり、この walkTokens は全てのトークンを走査する形で処理を挟むようになっている。もちろんこれらのパイプラインに我々実装者側が容易にプラグインなり処理を挟むことができるようにはなっていて、今回書く内容もそれに則った形になる。
今回は、これに沿って以下のカスタムルールを作る。
- Twitter renderer
- OG renderer
Twitter renderer
まずは Twitter renderer、どういうシンタックスにしようか微妙に迷ったが、
@twitter(https://twitter.com/takurinton/status/1234567890)
1
のような形で記述をすると、Twitter の埋め込みができるようにするようにした。
カスタムルールとは少し別の文脈になるが、Twitter の埋め込みには JavaScript API のページにあるスクリプトを書いて実装をした。
extension の定義
extension の定義をする。
使い方としては、
marked.use({ extensions: [twitter] });
1
で上記のシンタックスを使うことができるようにしたい。
具体的な実装については、Custom Extensions から下くらいが参考になる。
最終的には以下のようなコードになる。
const twitter = {
name: "twitter",
level: "block",
start(src) {
return src.match(/^@twitter\[.*\]$/)?.index;
},
tokenizer(src, tokens) {
const rule = /^@twitter\[(.*)\]/;
const match = rule.exec(src);
if (match !== null) {
const token = {
type: "twitter",
raw: match[0],
text: match[1],
id: match[1].split("/").pop(),
tokens: [],
};
this.lexer.inline(token.text, token.tokens);
return token;
}
},
renderer(token) {
return `<blockquote class="twitter-tweet" id="${token.id}"></blockquote>`;
},
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
これについて、lexer は定義していないので tokenizer と renderer について説明する。
tokenizer
tokenizer は src と tokens を受け取ることができる。src というのは 走査してる途中の文字列を受け取ることができ、tokens はその時点までに lexer で生成されたトークンの配列が渡される。
src は正規表現でルールを作成したい場合、tokens は親のトークンにアクセスしたい場合(ネストしてる list や table の styling/syntax の定義など)に使う。
今回は、src から正規表現でマッチングをして、マッチしたらそれを lexer に渡したあと、token を返すようにした。
この token は renderer に渡される。
また、このトークンのオブジェクトは自由に定義することができ、今回は id という Twitter の埋め込みの id を持たせておくことにした。
renderer
上でも書いたが、renderer は token を受け取ることができる。
今回は、Twitter の埋め込みの id を持っているので、それを使って埋め込みをするようにした。
ここでの戻り値がそのまま html string として最終的な出力になる。(しかし非同期関数を使ってる場合は別、後述します)
安易かもしれないが、これを .tsx のような拡張子の中で定義して、JSX.Element を返すような拡張を作って全てのシンタックスを上書きしたら面白いライブラリになるのではないかと勝手に思っている。
実際の出力
@twitter(https://twitter.com/takurinton/status/1234567890)
1
のような記述をすると、
<blockquote class="twitter-tweet" id="1234567890"></blockquote>
1
のような出力になる。
しかしこのままだと Twitter のカードはレンダリングされてくれないので、JavaScript API を使って埋め込みをする必要がある。
今回は特にフレームワーク等を使った実装を考えていないが、少々荒削りなことにはなるが例えば React を使うと以下のような実装にすると良いように感じる。
また、window.twttr.widgets.load の引数に ref 等のを指定すると、その子要素の中から blockquote.twitter-tweet を探してくれるが、今回は tweet の id を id として渡しているので querySelector を使って取得し、createTweet 関数で生成する形にした。
import React, { useEffect, useRef } from "react";
function App() {
useEffect(() => {
window.twttr.ready(() => {
window.twttr.widgets.load();
const twitters = document.querySelectorAll("blockquote.twitter-tweet");
twitters.forEach((twitter) =>
// 上で受け取った id を使って埋め込みをする
window.twttr.widgets.createTweet(twitter.id, twitter)
);
});
}, []);
return <div dangerouslySetInnerHTML={{ __html: html }} />;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
OG renderer
次に、OG renderder を実装する。
OGP は Open Graph Protocol の略で、SNS などでリンクを貼ったときに表示されるプレビューのことを指す。
以下のシンタックスで記述すると、OGP のプレビューを表示することができることを想定している。
@og(https://takurinton.dev)
1
実装方法は Twitter とほぼ同じで、正規表現でマッチングして、マッチしたら tokenizer でトークンを生成して、renderer で html を生成するようにしている。
const og = {
name: "og",
level: "block",
start(src) {
return src.match(/^@og\[(.*)\]/)?.index;
},
// eslint-disable-next-line no-unused-vars
tokenizer(src, tokens) {
const rule = /^@og\[(.*)\]/;
const match = rule.exec(src);
if (match !== null) {
const token = {
type: "og",
raw: match[0],
url: match[1].trim(),
html: "",
tokens: [],
};
// @ts-ignore
this.lexer.inline(token.text, token.tokens);
return token;
}
},
renderer(token) {
return token.html;
},
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
async
ここで 1 つ問題になってくるのが、fetch 関数が非同期で呼ばれること。
これについては、今年 8 月 30 日にリリースされた marked@4.1.0 以降で async walkTokens を使うことができるのでそれで対応を行った。
walkTokens は先述した通り、全てのトークンを走査する。そのためトークンが og の時のみ fetch をするようにした。
getHtml 関数は fetch して、最終的な OGP の html を返す関数を想定している。
{
async: true,
async walkTokens(token) {
if (token.type === "og") {
// getHtml 関数は fetch して、最終的な OGP の html を返す関数を想定
const html = await getHtml(token.url);
token.html = html;
}
},
}
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
これらを統合すると、以下のようにして書くことができる。
const og = {
extensions: [
{
name: "og",
level: "block",
start(src) {
return src.match(/^@og\[(.*)\]/)?.index;
},
tokenizer(src, tokens) {
const rule = /^@og\[(.*)\]/;
const match = rule.exec(src);
if (match !== null) {
const token = {
type: "og",
raw: match[0],
url: match[1].trim(),
html: "", // 後から warkTokens で埋める
tokens: [],
};
this.lexer.inline(token.text, token.tokens);
return token;
}
},
renderer(token) {
// ここでは空の html が返る
return token.html;
},
},
],
async: true, // async walkTokens を使うために必要
async walkTokens(token) {
if (token.type === "og") {
const html = await getHtml(token.url);
// renderer で一旦空の html を返していたので、ここで埋める
token.html = html;
}
},
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
このようにすることで、非同期な処理や関数を挟むことができるようになる。
この機能が入ったのは比較的最近だが、議論自体は 2014 年から行われており、async renderer support #458 で観測することができる。
このような実装やドキュメントの更新に尽力してくれてる marked チームには頭が上がらない。
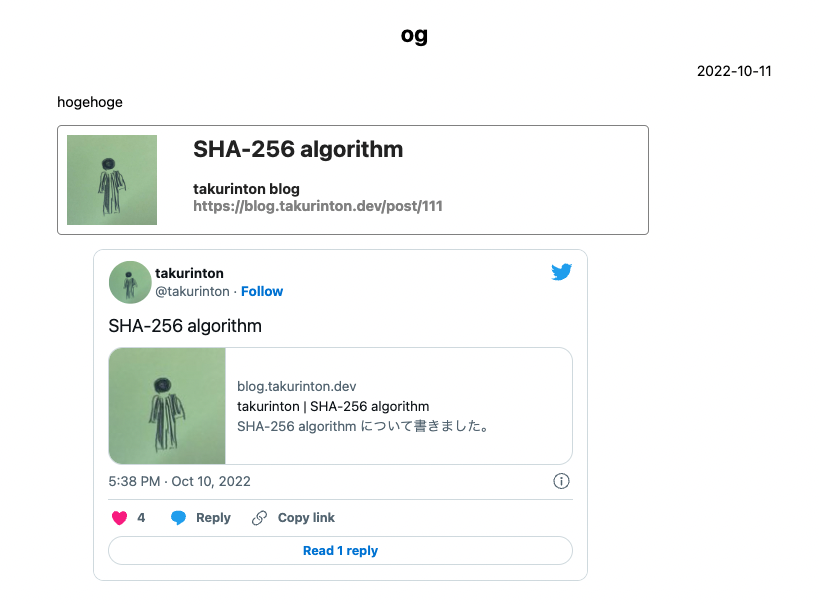
最後に
上記の 2 つのカスタムルールを定義した上で、以下のような markdown を渡すと、以下のようなレンダリングがされるようになった。
hogehoge
@og[https://blog.takurinton.dev/post/111]
@twitter[https://twitter.com/takurinton/status/1579390918603706368]
1
2
3
4
5
2
3
4
5
今回は lexer 等には触れなかったがここらへんに手をつけるのも自由度が高くて面白いので、今後も色々と試していきたい。
また、オレオレ parser でも似たようなことができるようにしたい。