Appearance
クラスタについて
2021-05-23
クラスタ分析
クラスタ分析とは対象間の距離を定義して距離の近さによって対象を分類する統計手法の一つである。
簡単に言うと似たもの同士を見つけるための方法である。
クラスタ分析には階層的クラスタリングと非階層的クラスタリングの2種類がある。
クラスタについて
そもそもクラスタとは何かについてだが、クラスタとは集団、郡などの意味を持つ。
また、人間が任意の条件で分類したものはクラスタではなくグループと呼ぶ。例えば小学生の運動会の赤組、青組などはグループである。
クラスタは距離の近さによって分類する手法なので、似たもの同士で分類しているという感じである。分類する側に人間の意思が働けばグループ、そうでなければクラスタと考えていい。
階層的クラスタリング
階層的クラスタリングでは結果はデンドログラムとして扱われる。デンドログラムは完全クラスタリングと呼ばれ、完璧にクラスタリングされる。デンドログラムはスポーツなどのトーナメント表のような形で表現される。完全クラスタリングを実現する代わりに、データ量が多いと時間がかかってしまう。
階層的クラスタリングのアルゴリズムは最短距離法、最長距離法、群平均法、ウォード法がある。一般的に計算量は 𝑂(𝑁2log𝑁) とされている。 ただし、Lance-Williamsの更新式で定数時間で距離の更新が可能な上記の距離更新手法には可約性 (reducibility) という性質があり,再近隣グラフの性質を活用することで 𝑂(𝑁2) の時間で計算可能なアルゴリズムが知られている。
python でのデンドログラムの表現
python ではデンドログラムがとても簡単に表現することができる。
使用するライブラリは pandas、numpy、matplotlib、scipy である。
今回は乱数を使用してクラスタリングを行う。
import pandas as pd
import numpy as np
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
import matplotlib.pyplot as plt
df = pd.DataFrame(np.random.rand(16*21).reshape(21,16)) # 適当な値を格納する
Z = linkage(df, method='ward', metric='euclidean')
1
2
3
4
5
6
7
2
3
4
5
6
7
Z を出力すると以下のようになる。コメントアウトしてる部分が出力結果である。
print(Z)
# [[11. 16. 1.07569096 2. ]
# [10. 19. 1.20989437 2. ]
# [ 4. 15. 1.24983718 2. ]
# [ 6. 14. 1.27961914 2. ]
# [22. 23. 1.30262426 4. ]
# [ 8. 12. 1.30865321 2. ]
# [ 7. 13. 1.31970314 2. ]
# [ 1. 2. 1.3569622 2. ]
# [ 5. 18. 1.36003759 2. ]
# [ 0. 20. 1.38985074 2. ]
# [17. 21. 1.59515131 3. ]
# [28. 30. 1.62814148 4. ]
# [ 3. 26. 1.65895643 3. ]
# [ 9. 27. 1.75510187 3. ]
# [25. 29. 1.90373766 6. ]
# [31. 33. 2.01135602 6. ]
# [24. 35. 2.1351386 8. ]
# [32. 36. 2.16289886 10. ]
# [34. 38. 2.25559914 13. ]
# [37. 39. 2.49505445 21. ]]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
また、これを使用してデンドログラムを作成する。
dendrogram(Z)
plt.show()
1
2
2
たったこれだけである。
出力結果は以下のようになる。
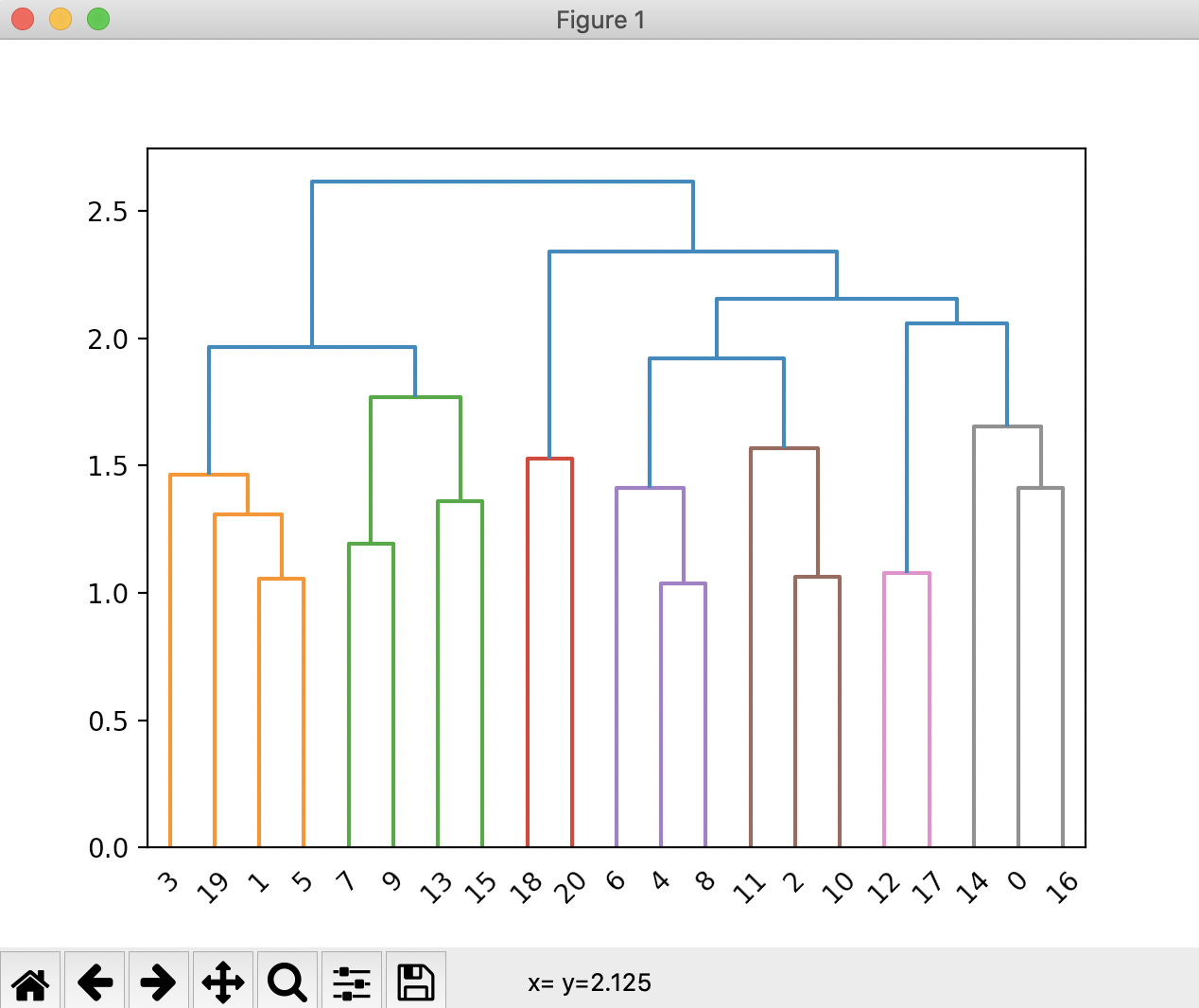
これは下に行けば行くほど似ている、上に行けば行くほど似ていないことを表している。
非常に簡単にデンドログラムを表示することができた。
非階層的クラスタリング
非階層的クラスタリングは結果がデンドログラムではなくただ単にグルーピングがされた状態で表される。
非階層的クラスタリングでは k-means 法が有名である。
python での非階層的クラスタリング
あまりにも k-means 法が有名なので自力実装しようと思ったが授業の時にやってめんどくチェ〜ってなった記憶が蘇ってきたので自分用メモとして sklearn を使用して簡単に実装する。
全体像は以下のような感じ。インターネットの海に落ちていた卸売業のユーザーデータを使用してみた。これはどの記事を参照しても使われていたので多分 hello world 用なんだと思う、知らんけど。
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
# ネットに落ちてた卸売業の顧客データ
# Fresh, Milk, Grocery, Frozen, Detergents_Paper, Delicassen
cust_df = pd.read_csv('http://pythondatascience.plavox.info/wp-content/uploads/2016/05/Wholesale_customers_data.csv')
del(cust_df['Channel'])
del(cust_df['Region'])
print(cust_df)
# Fresh Milk Grocery Frozen Detergents_Paper Delicassen
# 0 12669 9656 7561 214 2674 1338
# 1 7057 9810 9568 1762 3293 1776
# 2 6353 8808 7684 2405 3516 7844
# 3 13265 1196 4221 6404 507 1788
# 4 22615 5410 7198 3915 1777 5185
# .. ... ... ... ... ... ...
# 435 29703 12051 16027 13135 182 2204
# 436 39228 1431 764 4510 93 2346
# 437 14531 15488 30243 437 14841 1867
# 438 10290 1981 2232 1038 168 2125
# 439 2787 1698 2510 65 477 52
# [440 rows x 6 columns]
# numpy で扱える形式に変換
cust_array = np.array(
[
cust_df['Fresh'].tolist(),
cust_df['Milk'].tolist(),
cust_df['Grocery'].tolist(),
cust_df['Frozen'].tolist(),
cust_df['Milk'].tolist(),
cust_df['Detergents_Paper'].tolist(),
cust_df['Delicassen'].tolist()
],
np.int32
)
# 行列を転置
cust_array = cust_array.T
# クラスタ分析を実行(クラスタの数は4つ)
pred = KMeans(n_clusters=4).fit_predict(cust_array)
print(pred)
# 各顧客にクラスタ番号 { 0 || 1 || 2 || 3 } が付与されている
# [2 2 2 2 0 2 2 2 2 1 2 2 0 0 0 2 1 2 2 2 2 2 0 3 0 2 2 2 1 0 2 2 0 0 2 2 0
# 1 1 0 0 2 1 1 2 1 1 3 2 1 2 2 0 1 0 2 1 1 2 2 2 3 2 1 2 1 2 0 2 2 2 0 2 0
# 2 0 2 1 2 2 2 1 2 0 2 3 3 0 2 0 2 2 1 2 1 2 2 2 2 2 1 1 2 0 2 2 2 1 2 1 2
# 1 2 2 2 2 2 2 0 2 2 2 2 2 0 0 2 0 2 0 2 2 2 2 2 2 2 2 2 2 2 0 0 2 2 1 2 2
# 2 0 2 2 2 2 2 1 1 2 2 1 2 2 2 1 2 1 2 2 2 2 1 1 2 1 2 2 0 2 2 2 2 3 1 3 2
# 2 2 2 2 1 2 2 2 1 2 2 0 2 2 2 1 1 0 2 2 1 2 2 2 1 2 1 2 2 2 1 1 2 1 2 2 2
# 2 2 2 2 0 2 2 2 2 2 0 2 2 2 2 2 2 0 0 0 2 2 2 1 2 2 2 2 2 1 2 0 1 0 2 2 0
# 0 2 2 0 2 1 1 1 0 1 2 2 2 2 0 2 2 0 2 2 2 2 2 0 0 0 0 2 2 2 0 2 2 2 1 0 2
# 2 2 2 2 2 1 2 2 1 1 1 2 2 1 2 0 1 2 2 1 2 2 2 1 2 2 2 2 0 0 2 2 2 2 2 1 0
# 1 2 0 2 2 2 2 2 2 2 1 2 2 1 0 2 1 2 1 2 1 2 2 0 1 1 2 2 2 2 2 2 2 2 2 0 2
# 0 0 2 2 2 2 1 0 2 2 0 2 0 2 1 2 2 0 2 2 2 2 2 0 2 2 1 2 2 2 2 0 0 0 2 2 0
# 1 2 2 2 2 2 2 2 2 1 2 1 2 2 2 0 2 2 2 1 0 2 2 2 2 0 2 2 0 0 1 2 2]
# 確認する
cust_df['cluster_id'] = pred
print(cust_df)
# ↓こいつが追加されている
# Fresh Milk Grocery Frozen Detergents_Paper Delicassen cluster_id
# 0 12669 9656 7561 214 2674 1338 0
# 1 7057 9810 9568 1762 3293 1776 0
# 2 6353 8808 7684 2405 3516 7844 0
# 3 13265 1196 4221 6404 507 1788 0
# 4 22615 5410 7198 3915 1777 5185 2
# .. ... ... ... ... ... ... ...
# 435 29703 12051 16027 13135 182 2204 2
# 436 39228 1431 764 4510 93 2346 2
# 437 14531 15488 30243 437 14841 1867 1
# 438 10290 1981 2232 1038 168 2125 0
# 439 2787 1698 2510 65 477 52 0
# [440 rows x 7 columns]
# id = 0 のクラスタ
print(cust_df[cust_df['cluster_id']==0].mean())
# Fresh 42117.285714
# Milk 46046.142857
# Grocery 42914.285714
# Frozen 10211.714286
# Detergents_Paper 17327.571429
# Delicassen 12192.142857
# cluster_id 0.000000
# dtype: float64
# matplotlib で可視化する
# 何を買っているかがわかりやすくなる
import matplotlib.pyplot as plt
clusterinfo = pd.DataFrame()
for i in range(4):
clusterinfo['cluster{}'.format(str(i))] = cust_df[cust_df['cluster_id'] == i].mean()
clusterinfo = clusterinfo.drop('cluster_id')
my_plot = clusterinfo.T.plot(kind='bar', stacked=True, title="Mean Value of 4 Clusters")
my_plot.set_xticklabels(my_plot.xaxis.get_majorticklabels(), rotation=0)
plt.show()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
コードの内容はコメントに書いたので省略する。
大体の方法は掴んだのでよかった。 グラフは以下のようになった。
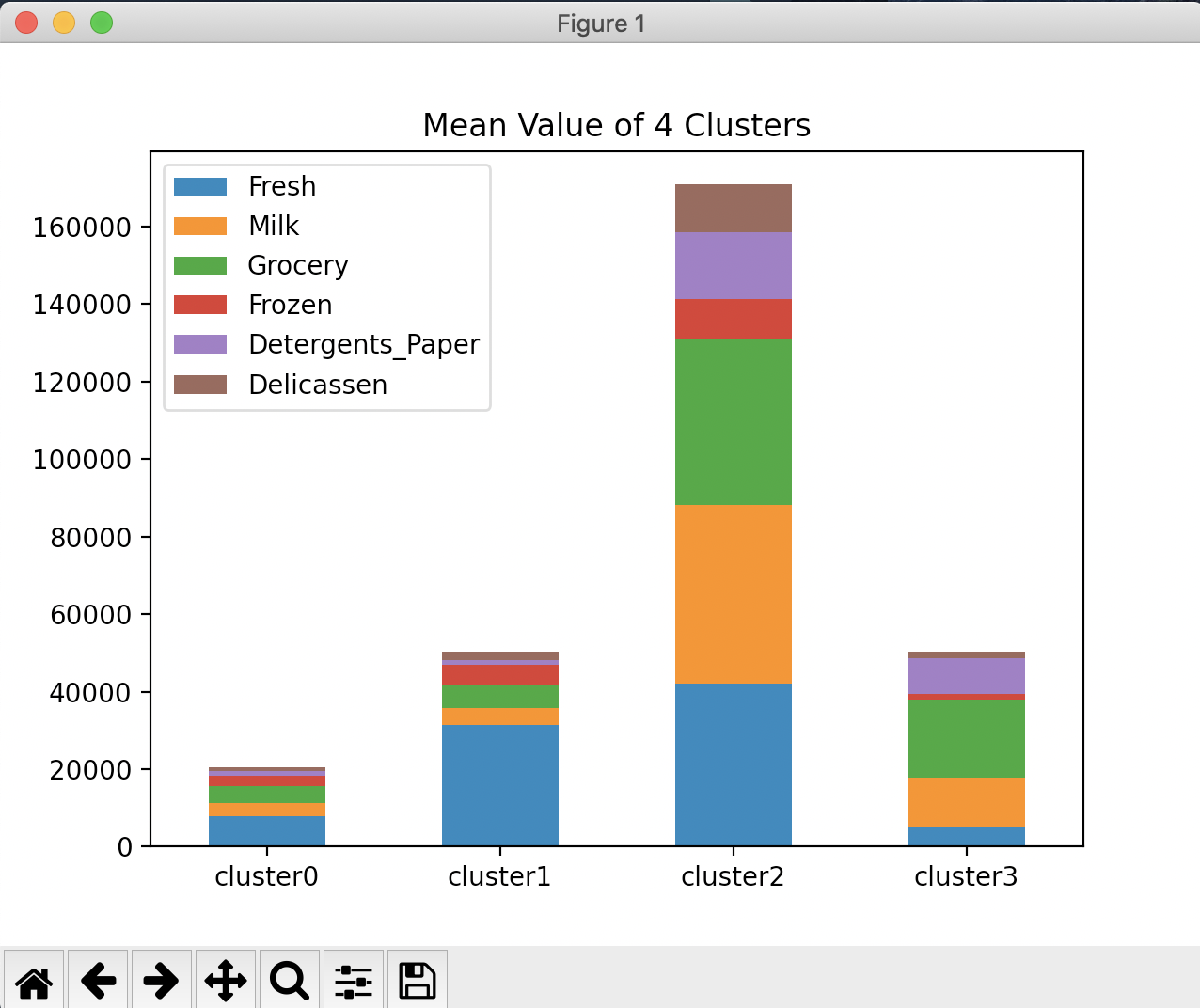
画像からざっと読み取るあたり、
- id=0 に分類されたユーザー (79 人) は、Grocery (食料雑貨品) と Detergents_Paper (衛生用品と紙類) が比較的高い
- id=1 に分類された顧客 (291 人) は、全体的に購買額が低い傾向にある
- id=2 に分類された顧客 (7 人) は、全てのジャンルで購買額が高い
- id=3 に分類された顧客 (63 人) は、Fresh (生鮮食品) やFrozen (冷凍食品) の購買額が比較的高い
といった感じでしょうかね〜〜〜〜〜〜。グラフあった方がわかりやすい。