Appearance
SVM について
2021-06-11
ラボで SVM について簡単な講義があった。それをもとに SVM について簡単にまとめる。
実装方法ではなくて、あくまで知識としてまとめておくみたいな感じ。実装に関しては別メモまたは Zenn とかの記事にする。
SVM の重要なキーワード
SVM にとって重要なキーワードについてまとめる。
スケーリング
特徴量の取りうる範囲が非常に大きい時に、範囲を予め調整することをスケーリングという。
大きな値をとるときに値が引きずられないようにする。外れ値を除外するのとはまた別の話。
これは次に出てくるカーネル関数で内積の計算をするときに情報落ちを防ぐ目的がある。
具体的にはそれぞれの素性ごとで 0 ~ 1 までの範囲に収めるという感じ。
例えば、身長(0~200) と視力(0~2.0) を素性として持っているデータの中に以下のようなデータがあるとする。
| 身長 | 視力 | |
|---|---|---|
| A | 180cm | 2.0 |
| B | 150cm | 0.1 |
このように大きな値をとってしまうとおかしくなってしまうため、以下のようにスケーリングする。
| 身長 | 視力 | |
|---|---|---|
| A | 0.9 | 1.0 |
| B | 0.75 | 0.05 |
このようにすることで大きな値を整形することでよしなに計算することができるようにする。
カーネル関数
データを2クラス(2クラスなので線形に分離する)に分類できる SVM を見つけるためにデータの配置などを変形するための関数をカーネル関数という。
上でも述べたが、内積を使用して計算する。
Wikipedia では以下のように紹介されている。
カーネル法(カーネルほう、英: kernel method)はパターン認識において使われる手法の一つで、 判別などのアルゴリズムに組み合わせて利用するものである。よく知られているのは、サポートベクターマシンと組み合わせて利用する方法である。 パターン認識の目的は、一般に、 データの構造(例えばクラスタ、ランキング、主成分、相関、分類)を見つけだし、研究することにある。この目的を達成するために、 カーネル法ではデータを高次元の特徴空間上へ写像する。特徴空間の各座標はデータ要素の一つの特徴に対応し、特徴空間への写像(特徴写像)によりデータの集合はユークリッド空間中の点の集合に変換される。特徴空間におけるデータの構造の分析に際しては、様々な方法がカーネル法と組み合わせて用いられる。特徴写像としては多様な写像を使うことができ(一般に非線形写像が使われる)、それに対応してデータの多様な構造を見いだすことができる。
写像って何ですか???
まあそれはいいとして...。
こんな感じで線形に分離することができない時に使用する。
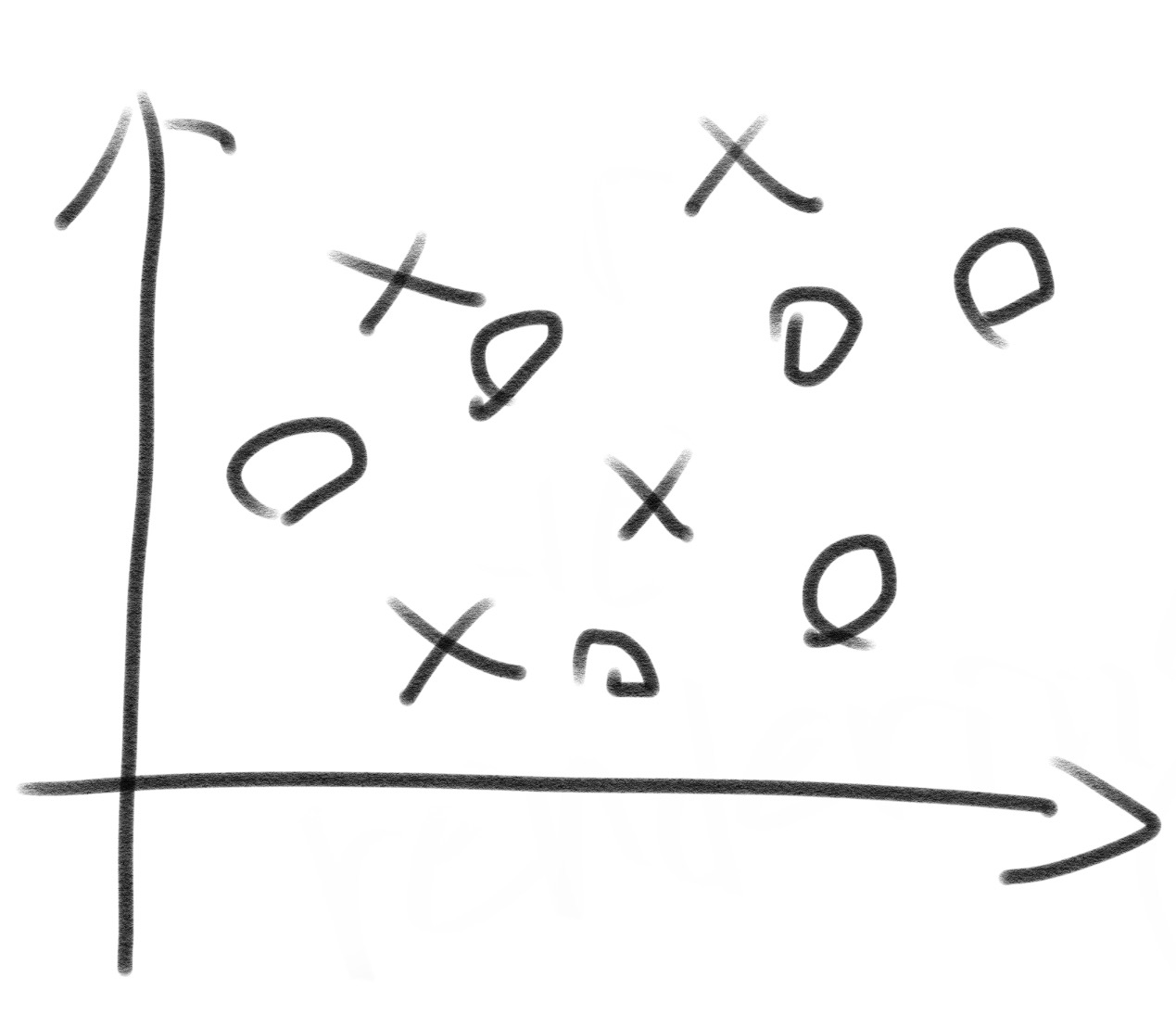
カーネル関数は以下のようなものが有名である。
- 線形カーネル
- 多項式カーネル
- RBF カーネル(特によく使う)
- シグモイドカーネル
クロスバリデーション
性能評価の際にデータ数が少なくて訓練データとテストデータの両方を用意するのが難しい場合、クロスバリデーションを使用するとより正確に実験を行うことができる。
学習をする際により良い結果が欲しい時に利用する。
注意点として、5分割でクロスバリデーションを実施する際、時系列データを使用するとおかしくなってしまうのでそこは気をつける必要がある。
これはまあ自分では理解してるから簡単に触れてスルー。
不均衡データと過学習
2つのクラスのデータ数が大きく異なる場合に、データ数の多い方のクラスの分類されてしまうことが多い。このようなデータを不均衡データという。
不均衡データを扱う際、例えば、クラスAとBがあって、Aが90%、Bが10%あり、Bについて確かめたい時に、全体の Accuracy はAが90%になるけどそれは必ずしも正しいとは限らないよね、逆に適切に補正された手法を用いると Accuracy は下がるかもしれないけど真陽度は増すよねみたいな感じのことが考えられる。
ここら辺の分類を行うことが不均衡データでは重要。不均衡データを分類するときの目的はデータ数が少ない方のクラスを正しく特定すること。
大きい方のクラスを小さい方のクラスに揃えることをアンダーサンプリングといい、逆に小さい方のクラスを大きい方のクラスに揃えることをオーバーサンプリングという。
SVM にはコストを表すパラメータCがある。これは各クラスごとに設定することができ、Cの値を大きくすると誤判定に厳しくなる。
なんとか分類することができるように学習を繰り返すので、少ない方のクラスのCを大きくするとデータ数の少なさをカバーすることができる。
ただし、これは過学習が起きやすくなるので注意が必要。
過学習とは学習のしすぎて偏りが生まれてしまい汎用性がなくなること。
人間でも起きる、教科書通りにしか物事をこなせない人はこのタイプ。
データ数が大きくなると外れ値が一定数存在することは避けられないため、過学習にならないように注意してCを決める必要がある。
SVM の評価指標
SVM の評価指標は4指標ある。
| 真の時ポジティブ | 真の時ネガティブ | |
|---|---|---|
| ポジティブ | TP(True Positive) | FP(False Positive) |
| ネガティブ | FN(False Negative) | TN(True Negative) |
これらの値は以下のようになる。
- 正答率(Accuracy)
- (TP + TN) / (TP + FP + FN + TN)
- 全てが正しい分類をされてるかどうかを確認する
- 適合率(Precision)
- TP / (TP + FP)
- ネガティブの誤判定が多くても小さい値になる
- ポジティブとして出てきたデータが本当にポジティブかどうかが見える
- この値が0だったらポジティブの品質は担保されてるということになる
- 再現率(Recall)
- TP / (TP + FN)
- ネガティブの誤判定には影響されない
- Accuracy において、ポジティブの値がどれだけポジティブとして判定されたかを見ることができる
- F値(F-measure)
- (2 * Precision * Recall) / (Precision + Recall)
- 一般的に、適合率が上がると再現率が下がる、その逆も然り
- 両者のバランスの程度を評価するのが F値
- 適合率と再現率が両方100%の時、F値は1.0(100%) となる